Small update to keep myself honest on updating this blog.
Quick side BBCF update
But first, a quick small BBCF update: I decided to do Haz-only in a few tournaments for a bit because I wasn't feeling swapping to Terumi only for tournaments. I went 4-2 at my locals! A lot of the very strong players were missing, but still -- I held my own through 16 games and didn't let the nerves get the best of me. And I beat my fellow hazama player who has been helping me! It was extremely close and two very fun sets.
I've still got several glaring issues in my Haz gameplay I want to fix, but at least this has really shown me (again?) that yes, I can play this character. I may stick with him for a bit, because I keep getting chastised for swapping constantly between characters, and come back to Terumi once I've gotten a better handle on fundies.
I may commission an icon of my lil hazama design to celebrate yesterday. Still can't believe I actually did it...
Replay Project
As previously mentioned, one of my big projects centers around processing and storing replays. I've made a lot of progress UI-wise on the thing. I now have a window that can load backed-up replays from a particular folder and its subfolders, process all of those replays into ReplayHeader objects, and display them.
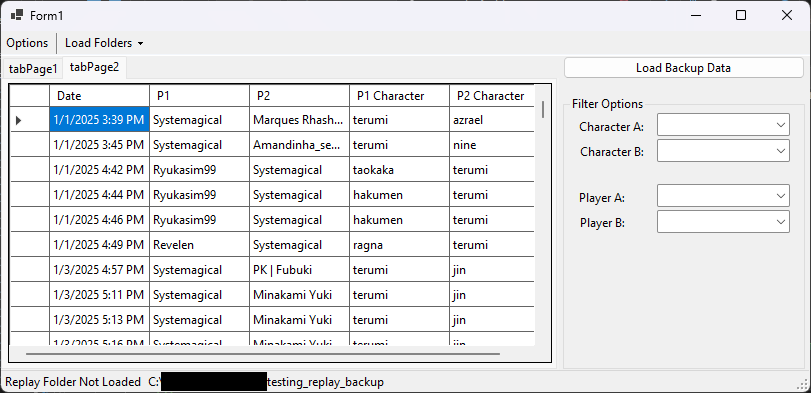 This example loads in approximately 3.7k replays in less than 5 seconds. Yes, I have that many replays backed up. My oldest saved replay is from December of last year.
This example loads in approximately 3.7k replays in less than 5 seconds. Yes, I have that many replays backed up. My oldest saved replay is from December of last year.
I've also added a sub-window that takes my chaos replay backups (literally me ctrl + c'ing my Save folder and pasting it into a folder in a new subfolder) and sorts it out to only the unique replays and renames them.
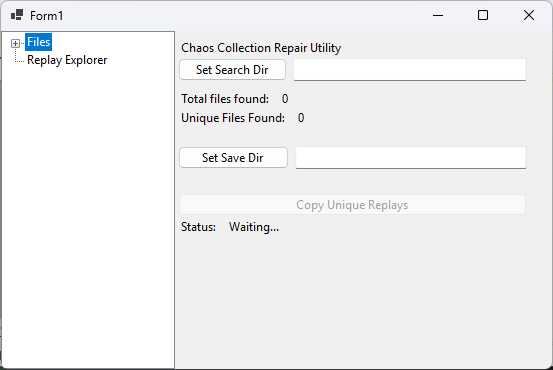
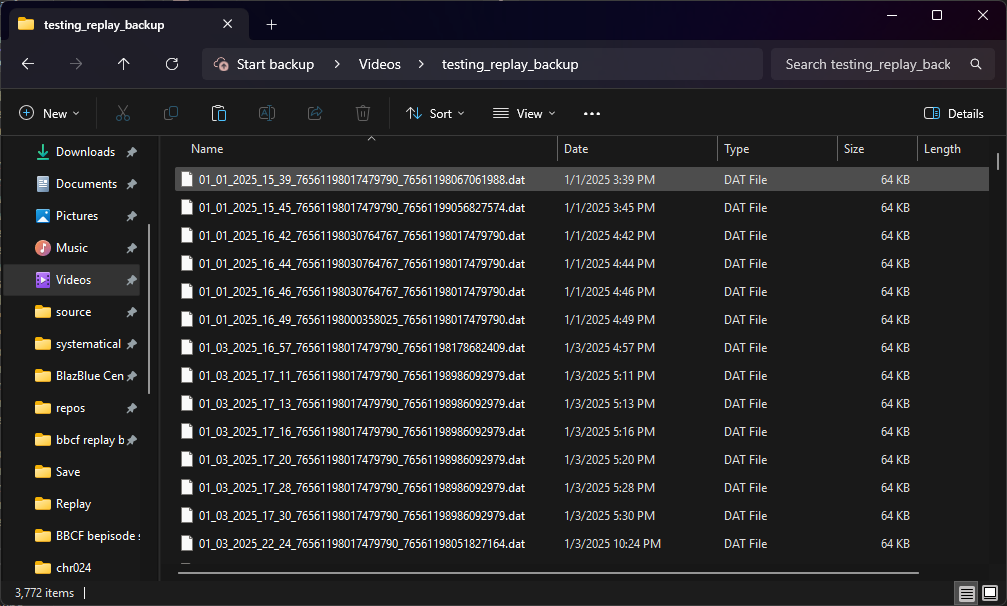 The names look like nonsense, but they can be broken up like this: date_p1steamid_p2steamid. The reason I use steamids instead of usernames is because people love to name themselves silly things that aren't valid characters to put in a filename.
The names look like nonsense, but they can be broken up like this: date_p1steamid_p2steamid. The reason I use steamids instead of usernames is because people love to name themselves silly things that aren't valid characters to put in a filename.
There's still a few things I need to work on.
- The list isn't properly sorting by date yet, I don't think. I believe it's still treating it like a string, not an actual date object.
- There's no filtering.
- There's no way to pick replays and load them into the replay folder.
Data Binding
Parts 1 and 2 are a little complicated, and that requires going into how I made the display. I'm using a DataGridView, which can take a BindingSource, so it updates whenever anything is added and removed. But the problem is, BindingSources don't have any sorting or filtering functionality, unlike Lists. There's some third party classes that implement sorting/filtering, but these are pay for, and I'm not doing that for this silly little pet project.
I'm considering two options: either see if I can bind the DataGridView directly to a List and just force the DataGridView to update myself (by re-setting its binding), or write some subclass of BindingSource that adds a sorting function.
(I'm almost certainly doing the first one. I'll just need to see how bad the performance is. It's way easier for the second one to have horrible performance, so I don't want to risk it.)
You may wonder why I'm worrying about performance. Unfortunately, it does kind of matter in this case. Before a DataGridView, I used just a ListView, and the ListView took over 40 seconds to populate. So... I want to avoid that.
replay_list.dat
I kind of skipped a big part of this whole project in the beginning in all of this description. Some madlads who actually read this blog and understand my ramblings may remember that it's not enough to just have the replay[0-9]+.dat files -- BBCF also expects a replay_list.dat file. I'd already found that the replay_list.dat is literally just a collection of the header data from the replay files -- hence why I made ReplayHeader objects, not Replay objects. I don't need to care about parsing anything past that header (though at this rate, I will.)
I also need to update the 2-byte checksum at the very beginning of the file, but I was given C# code on how to do this. I just actually need to add this part now. I have a program that can load in a folder of backed up replays, I need to now make it so that it can take a subset of those, create a dummy replay_list.dat file, and put everything into the correct locations. Shouldn't be too hard, but I always hesitate in saying for certain.
I'll also need to add UI capabilities for a user to be able to select which replays to copy. That shouldn't be too bad, because I'm fairly certain you can select rows in DataGridView. If anything, I may be able to add a column of checkboxes and just take the first 100 rows with a checked checkbox.
I should also paginate the data, but for now I'll avoid that because that adds complexity. What if a user selects 5 from one page, 5 from 2 pages past that, and 90 from three pages past that? It'll be doable, I just need to make the structure to handle all that, which I don't want to yet.
(Though, if I do that, it may make it so I can use something other than a DataGridView so I can do better replay selectability since I only have to load, say, 50 replays at a time rather than all 3.7k.)
Other Deets
I eventually want to start parsing the actual inputs to see if I can still force a replay to skip the intro. This is huge scope creep, but it shouldn't be too bad because Xinput seems fairly standardized. I also noticed that there's some neat information available in the IM about current frame, and that counts backwards, so that might have been the hint I needed to figure out how to parse the replay.
It also seems like every time I talk about this project to someone they completely don't understand why it's useful at all. I figured that something that lets you have more than 100 replays saved would be super obviously useful, but I guess I'm alone in that. I should make a pretty little document that describes it with pictures so I stop feeling stupid every time I describe it to a friend and they go "uh. okay."
Misc Tech Stuff
WSL dev
I've had a lot of luck developing on WSL lately. For some magical reason, docker just... works on both of my machines now. That's good!
The one issue I'm running into now is I'm being silly and starting an instance of a WSL terminal every time I want to have another folder open at the same time. I don't know the specifics of the performance and resource hit this causes, but I know it is there. I'm going to learn to use tmux so I can have just one instance running but vsplit and hsplit my way into imitating the tiling wm behavior I used to love on my linux laptop.
Docker
Every time I stop using docker and have to use it again I remember how much I hate it...
For my work I have to develop using an experimental branch of a piece of open-source software that is 3 minor patches behind the current release, and is specifically incompatible with other versions of logs generated by that software because the point of the branch is to add additional data to the logs.
But the point of this software is for HPC logging. My laptop and my desktop are not HPC machines and I do not want to install spack, an HPC package manager, on either of my development machines so that I can install the experimental version of this software.
So, I made a docker image! Easy, right?
No.
It was fucking miserable.
It's done now, and it's working, but note the fact that it takes over fifteen minutes to build the image, because spack is recompiling all of the dependencies from source. I don't know why! I don't want to ask at this point! The point is that this is causing frustrating issues because I finally set up GitHub actions to build the container on every push to dev and main (that contain changes in the share/docker subdir), and every time I have to wait fifteen minutes. (I also made it so it tags the image based on the branch it came from, which is neat.)
This technically shouldn't be an issue moving forwards, because I think I finally made good images. Note the plural. I've made two: a basic one that just gets you a docker with the dependencies installed for the sake of command-line testing (e.g. test that the package I'M developing installs properly) and a second "development" image. The development image is actually kind of cool and I'm pretty happy with it-- it has jupyter lab and when you boot it, it just spins up a jupyter lab instance you can connect to through the browser. This lets me do development on the actual package itself, because it needs to have the right version of the tool installed to even test or run sub-functions from. So, I use the first image to test if it works from start to finish, and I use the second image to manually test if a subfunction works and explore the internal variables as it's running.
I also learned about docker-compose.yml files, which is apparently a thing I was supposed to know about already. I've made one for the basic image and one for the development image that default attaches a volume to the source directory of the repository so I don't need to manually mount them. It also handles port forwarding.
(I may go back and add examples later, but right now all these changes are still on my laptop only so I can't fetch them right now.)
I also was extra nerdy and realized that there may be a quiet failure: if someone is developing on dev, the docker-compose.yml files have the main release of the docker image as default. If they're trying to develop against the dev version of the image, which may differ from main (in fact it does right now, because main doesn't even exist yet teehee). So, I created two .env files that can be provided whe running docker-compose.yml: .env that sets TAG to main, and a .env.dev that sets TAG to dev!
Yippee!
Hopefully I remember how to use these files in the future lol. Should be easier than remembering how to use docker build raw.
I also got the fun news that they're actually planning to finally merge the experimental branch into the main branch lmfao. So that's probably going to have to completely change my code, because they probably have to completely change the logs so they stop being incompatible.
AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAH.
Whatever. I'm only on this project for one more week. I just need to make sure I set my stuff to pull the specific commit before they start rebasing at the very least.
